Last updated
May 18, 2026
Last updated
May 18, 2026


It has been twelve years. We implemented our first text analytics algorithm back in 2010. I wonder if we would do the same if we knew everything that we know today. Maybe, but I’m not 100% sure. It took us a long time to build a market intelligence platform — an information aggregation and analysis platform. A platform for continuous monitoring of thousands of websites for new information on competitors, customers, industries, and other signals such as sales opportunities. In these years, I have met several organizations that are building or planning to build similar market intelligence tools. Because they have realized the need for such a platform and free software, such as these, can help in putting together some of the pieces of the puzzle. it’s easy to get started. We did the same. In one of the meetings with a potential client, their CTO smiled and said, “I can build this in one month with a team of five engineers!” I think he was not wrong, arrogant, but not wrong. It is one of those things that are deceptively simple to start but painfully difficult to finish. In such meetings, I usually explain the challenges that we faced. I also say that one day I will write a blog on this. So here it is. An introduction to the challenges that your teams should brace with humility in this journey of developing a market intelligence platform for information aggregation and competitive market analysis.
1: Sourcing of information
For sourcing information, the platform has to integrate with thousands of different websites and continuously monitor those websites to detect new information. There are several challenges a sourcing engine faces and they become even severe as we operate on a large scale. Here are a few:
Some of the websites are integration-friendly and have RSS feeds and APIs available. But most websites do not. They post information for humans to read, not for software to integrate and analyze. Therefore, we have to write different code for scraping different websites.
What makes it even harder to integrate with websites at a scale is that there are no universal standards for website development. There are guidelines and recommendations but no rules. No thanks to the companies fighting the browser war for monopoly, and not agreeing to standards.
Besides, the scraping is error-prone because modern websites are not simple HTML pages. They are “intelligent” web pages. They are responsive, dynamic, and personalized. They use cookies, JavaScript, AJAX calls, and other technologies to generate a unique web page for each user.
And just when we think that the scraper is working fine, the reality of the Internet hits us in the face. The website changes without any warning and our scraper goes for a toss. To make things worse, new web pages keep cropping up — a new section, a new blog, a new discussion forum, a new review site, and more. We continuously scout for new sources. We fear that someone “important” will find some information that our scrapers missed, and label our platform as unreliable. The interesting world of scraper development soon becomes a tedious world of scraper maintenance.
This makes sourcing the #1 challenge and web scraping a dark art that requires specialized skills.
2: Removing irrelevant information
Let’s assume that somehow the scraping is working just fine. Now we have to address a bigger challenge of removing information that is not relevant to our business, which is most of the information aggregated from the web.
Over the past seven years, we fine-tuned this process with a lot of heuristics and learnings from the data (and I should mention, at a very high technical and operational resource cost). Here are a few things we have learned:
First, the easy part. We remove the non-business information right at the source. Information such as crime, politics, entertainment, sports, etc. For example, we can remove the stories with the word “kill” in the title, these are usually crime-related. But careful, we can’t remove stories like “Google aims to kill passwords..”
To overcome such corner cases, we need new kinds of operators that are more intelligent than just matching keywords — something like “title_has_company” or “title_has_money”. Such custom operators give control to override the unintelligent logic based on just keywords such as “kill.”
Now, the difficult part. We have to remove information that is related to business but not relevant to our business. For example, information about our industry but from different geography, or information about our competitor but for a different segment where we don’t compete, you get the idea. And this opens Pandora’s box.
For example, let’s look at the simple task of separating information based on the location. To do this we need to identify the location in an article, take care of the wrong spellings, find the correct London out of all these other Londons, not tag Boston with the information about the Boston Consulting Group, and more. Even after doing all this, we cannot confidently separate information based on location because most business articles are without any location. For example, “Benchmark’s Uber Suit..” doesn’t have any locations. Now what?
We have to spend a lot of time with this ‘Now What?’. Sometimes, we get a eureka moment such as let’s use the location of the source as a proxy. For example, The Times of India will usually write about India, not Poland. But then it takes care of only a few situations and causes many errors. And we go back to ‘Now What?’
3: Removing duplicate or similar information
After addressing the irrelevant information problem, we have to deal with a more complex problem of detecting duplicate and similar information. Removing irrelevant information is still easier because we have to deal with just one individual piece of information. But for duplicates, we have to compare the new information with everything else in our database.
It is easier for technology to identify and mark duplicates when different articles use the same or almost the same words. Unfortunately, this is not how websites post information. Most websites post the same information with different words to appear unique to search engines and sometimes to avoid copyright violation. It is a nightmare for text-analytics professionals to identify and remove such information that is similar but not the same.
Here machine learning comes to our rescue. Standard programs are available for grouping similar articles. They use efficient clustering algorithms with reasonable accuracy. But sometimes they incorrectly group different articles or fail to group similar ones. Now what?
Many smart engineers at Google worked on this for several years. We struggled for a long time to identify some patterns or signals in the articles to group similar ones. In this case, our eureka moment was the realization that this cannot be achieved in a single step, it has to be done in multiple steps. First, group information based on standard algorithms, then ungroup based on the other signals in the article, such as the industry, the topic, the companies and people, the publication, the date of the articles and others. The accuracy improves with each step of grouping and ungrouping. But it doesn’t get any easier.
After successfully grouping (hopefully), we will realize that a less important article is at the top of the group. A better article is hidden under it within the homogeneous group called “similars”. We need to somehow make the algorithms understand which is the most important article in the group. And we go back to, Now What?
4: Identifying companies and persons
After dealing with the problem of duplicates and similars we have a clean data feed that is ready for further analysis. The next step is to identify companies and persons in the information. In the world of text analytics, this process is called Named Entity Recognition. While this looks seemingly simple to the human eye, teaching a machine to accurately recognize entities in an article is painfully complex.
One way to identify the names in an article is by looking for words that have the first letter in uppercase, For example, ICICI. We can achieve this with some elementary text processing. Now, if the following word also starts with a capital letter then it is a part of the same name, e.g. ICICI Bank. This could be true for the third word also, ICICI Bank Ltd. But not always, for instance, “ICICI Bank Q3 result is not good for text analytics”.
Rajiv Gandhi National Park is not Rajiv Gandhi the person, and to add to the misery, it is also known as Nagarhole National Park. There are other problems such as misspelled words and fancy foreign language words such as L’Oréal.
And there is more to it.
There are company names which are common nouns or popular words, such as Apple, Amazon, Gap. It is an entirely different science to recognize such companies in an article. For this, we need to again look for other signals in the article. Does it have any of the services or products of the company mentioned? Does it mention any company executive? Are there any competitors mentioned? Is it about the same industry as that of the company?
These common English words are the bane of the dark world of text analytics. Indeed, it is a problem or Indeed is a company. But it doesn’t get any easier.
5: Is it about the company or just a mention?
Let’s assume that somehow we managed to identify companies and persons. Now we can dare to look at the higher-order complexities of text analytics — the problem of aboutness. How do we know whether the story is about the company or just mentions the company? E.g. consider this line somewhere in the story: “Amazon, Microsoft, Google, and Oracle are also offering cloud computing solutions”. It’s a story with passing mention of Microsoft. We don’t want our competitive intelligence research users to get this in their updates for Microsoft.
One way to address this problem is to assign scores to all the companies in an article. This score is based on parameters like the word position of the company in the article, mentions of executives or products and services of the company, popularity of a company in media (how frequently a company appears in other articles over a period), and more.
Again, easier said than done. For each signal, we need a knowledge base for reference. For example, for products and services signals, we need a knowledge base of all the products and services of the company.
It is not a good idea to start developing and maintaining a knowledge base for each signal. We will need many as we aim for higher accuracy. Rather, we should find partners who can feed us such data for signals. Fortunately, many companies provide data feeds, which can be used as signals, via APIs.
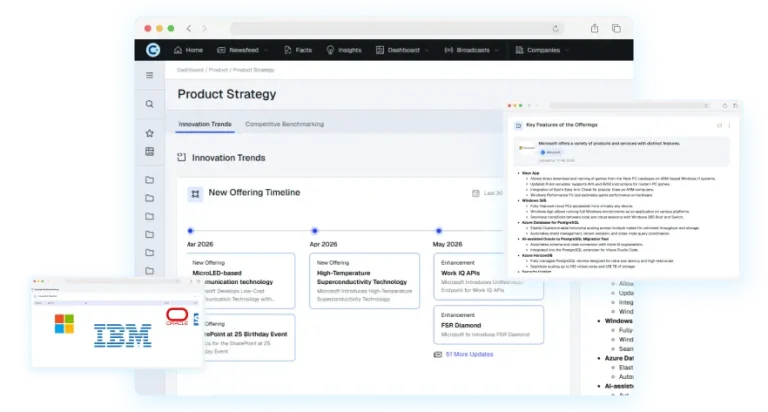
6: Industry and topics of the article
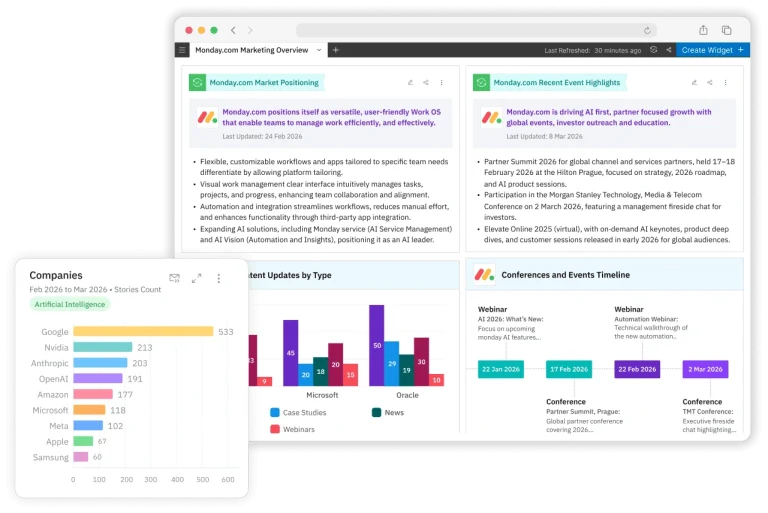
We answered whether it is about the company or not. Now we need to find which industry or topic is the article about. Why? How else can we find all the partnerships in an industry in recent months? Or the business expansion announcements by competitors? To answer these, we need a way to analyze the aggregated information by industries and topics, such as partnerships, business expansion, new offerings, and more.
Unlike the company or person, subjective categories like the industries or topics are not limited to a finite set of keywords. This cannot be achieved without using a mix of complex machine learning algorithms. We need to fine-tune the classification algorithms to recognize the pattern of words that are commonly used to describe an industry or topic. There is always a level of approximation in this. We will be damned if we tag a story incorrectly, and damned if we miss the tag.
Even in this, as we go deeper, we find increasing complexity. For example, say we correctly identified a story about an acquisition and also identified the three companies — the acquiring company, the acquired company, and the investment bank. Now, how do we find which one is the acquirer and which one got acquired? We don’t want this story when we are looking for acquisitions in the banking industry. Damn! We also need to preserve the relationships between the topic and these companies. And we go back to, ‘Now What?’.
7: How about social media?
For a change, it is easy to source information from social media. Most of them have integration friendly APIs. But that’s the end of the easy part. Rest everything is, as expected, overwhelming. To extract a few competitive market analysis insights from the millions of mindless shares and updates is like finding a needle in a haystack — but without a magnet. Our competitive intelligence research engine rejects more than 95% of social updates from companies.
In addition, there is an increasing number of social media sites with increasing complexity. Twitter, for example, has a tweet, then there is a retweet, a retweet with quotes, private tweets, important tweets from influencers like Rihanna, and ignorable tweets from Nobody Jones — ‘Now What?’
It is not easy to even find the right social handles to monitor. There are fake handles and then there are different handles of people and companies for different purposes. For example, IBM has social handles not only for different geographies but also for different functions within the geography such as IBM jobs in India (@IBMIndiaJobs). It has more than 100 Twitter handles (we don’t know the exact figure) — this lists 107 handles, but misses @IBMIndiaJobs!
Read our blog to get details about insights from social further.
What’s my point?
If you are planning to build a market intelligence platform, our blog on why we built Contify, a market intelligence platform, highlights some of the challenges and how we, at Contify, have addressed them. I can’t disclose much because then we can’t get a patent for the already published information. I have two points to make:
One: The Web is a goldmine of information, only if we know how to extract this gold that is buried under the mountain of irrelevant and duplicate information. It can’t be extracted by hand. We need sophisticated tools to dig it out. It is foolhardy to think that we can go and get the information whenever we need it because it is in the free web domain. Let me illustrate this with an example:
Apple’s business strategy section of the annual report had just two additional words in 2002 that were not there in 2001. These were “cellular phones”:
The company believes.. as the digital hub for advanced new digital devices such as digital music players, personal digital assistants, cellular phones, digital still and…
Yet, many were surprised when Apple, a computer company, launched the iPhone five years later.
Two: If offering a market intelligence platform is core to your business, you should go ahead and build such a competitive intelligence platform. If not, then building one would not be wise — even if you have a great technology team.
Remember, only you will have to fight this war with irrelevant information to get to the intelligent information. Your users can’t understand these challenges and hence won’t appreciate it. They will just see the relevant articles. But, if you miss any information your whole platform will be labeled as unreliable.
However, if getting this right is not a priority for your business and you love to jostle with technical problems, you can try to build one. This journey will leave you as a different (better) person, with a deeper appreciation for machine learning, and what it can or cannot do — an important understanding to have for future enterprises.
The answer to ‘Now What?’ is the same as the reason why Uber, with over USD 8 billion in funding, uses Stripe for payment processing, and Twilio for SMS messaging. You should think hard before deciding to build a competitive intelligence tool! Take a 7-day free trial of Contify’s Market and Competitive Intelligence Platform.