Last updated
Mar 3, 2026
Last updated
Mar 3, 2026


As a programmer with a data science background, my attention is invariably caught by the real-world situations where machine learning algorithms have made a difference, for example, email spam filtering, news categorization, review based recommendations, social media sentiments, etc. Time and again, I marvel at the simplicity of the optimizations that lead to massive pay-offs notwithstanding the complex nature of machine learning problems.With this post, I would like to walk you through one such example of a seemingly complex machine learning problem broken down using street-smart tools.
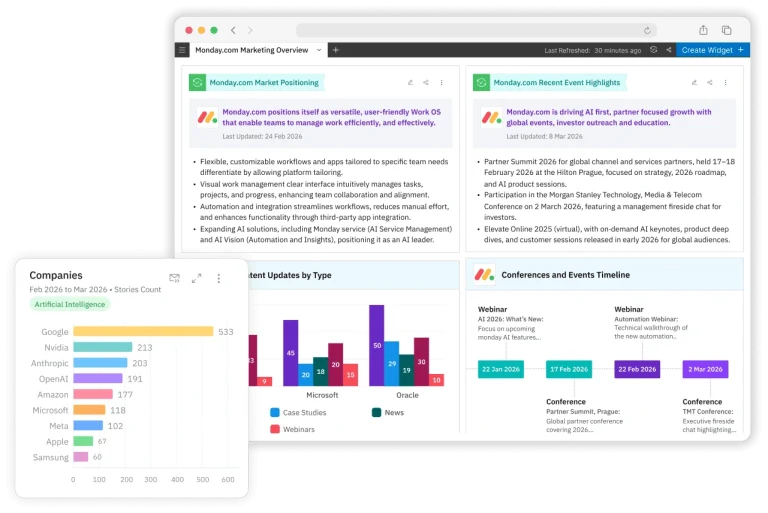
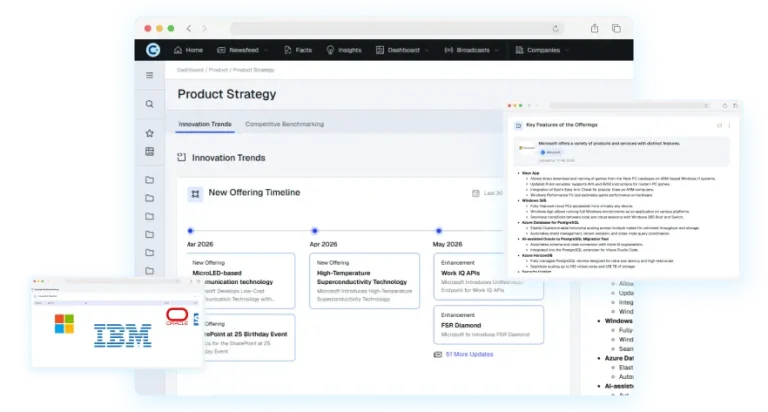
Our product, Contify, is an AI-enabled competitive intelligence tool that provides information (from web properties including social media) with high accuracy of tagging, which makes unstructured information “analyzable.” The edge, compared to traditional market analysis, is that our machine learning algorithms take the first pass and reduce human analyst efforts by a large fraction. We essentially perform three steps in the process:
1. Select relevant pieces of information from millions of sources across the web
2 Digest this information and assign custom tags, and
3. Assimilate this in an intuitive UI for consumption
How De-duplication Improves Machine Learning Efficiency
From the first look, anyone familiar with machine learning can spot that interesting application of machine learning fall in steps one and two.
However, a complicated high-impact application is in the first step itself. When the system gathers hundreds of thousands of documents from the Internet, it needs to chaff out those that have similar information but comes from multiple sources. These documents may have different text but they have the same information — just rephrased. It would be a gross waste of resources if we process all these documents individually.
So, we implemented de-duplication algorithms to significantly reduce the resources required to process the information in these documents. And here is how:

Once the documents are fetched into the system in the form of text documents, we convert them into vectors of document features. The features are based on the frequency and importance of entities among other things (discussed at a later point in this post). The matrix is then transformed into a similarity matrix using cosine multiplication. The rows of this matrix are the document ids and columns are values that represent how similar they are.
The next challenge is to cluster this large similarity matrix and look for similar documents. This is a unique clustering problem that requires us to find a large number of tight clusters of uneven cluster sizes. Most of the standard clustering algorithms fail to cluster in such a fashion. We, therefore, had to write our version of hierarchical clustering that returns a large number of tight clusters or duplicates. The thresholds have been tweaked based on real curated data from our analysts. We tuned the algorithm in hundreds of ways and validated it on thousands of human-curated documents. We are still tweaking and tinkering with the algorithm as new cases keep coming up. It’s a constant learning process.
It is important to understand that with the advent of easily available libraries for virtually all the problems at hand, the big difference in the performance of two algorithms depends heavily on feature selection. And to make things complex, the feature set for de-duplication varies substantially from that for tagging or classification or topic modeling.
At this point, I would like to share with you the components of a feature vector we used for de-duplication:
1. Entity Identification
We found that the simplest approach is to compare entity frequency vectors of a set of documents to be compared as duplicates. An entity could be a noun such as the name of a company, person, location, etc., a number (stripped of all 0s decimals and commas), a contiguous set of words (usually more than 3 causes performance issues).
Numerical values like financial figures and dates are usually important determiners of the similarity, but we didn’t use them because of the differences in their formats and units of their measurement at different places. We are working on different ways to use them in our feature set.
2. Title and Lead for News Articles
In news stories, the title and lead of the stories are usually important. Therefore, we simply increased the frequency count of entities that are present in the title and lead compared to the overall entities. This feature set has the most significant effect on the de-duplication performance.
3. Named Entities
A Parts Of Speech (POS) tagger is used to give higher weightage to named entities like companies, persons, locations, etc. At the moment we are evaluating the performance of de-duplication if we decide to move from a simplified proper noun extractor to the POS tagger.
4. Inverse Document Frequency
We can improve the term vector further by using inverse document frequency(IDF). IDF is an inverse function of the number of documents in which a term occurs. This gives higher weightage to unique words in the documents. For de-duplication, we found that by having a large feature vector, IDF can be ignored without a considerable loss in de-duplication performance.
5. Similar Meaning Words
A major problem in entity recognition is the possibility of multiple words that have similar meanings. An approach called latent semantic analysis allowed us to overcome this by factoring our term-document frequency matrix into a smaller semantic.
Each feature here can be understood as a combination of several terms of the original matrix that occurred simultaneously. Due to computational reasons, it is expensive to increase the number of features to more than 100. We use it for de-duplication only when the number of documents to be processed is smaller than 200.
6. Foreign Language Words
Of course, none of this works when we move to foreign-language content, especially for languages like Chinese and Japanese where there is no real concept of words. We used standard libraries to implement foreign language tokenization.
These work by building a graph for all possible word combinations and using dynamic programming to find the most probable combination based on the word frequency. Once we had our entity set, these foreign language documents fit seamlessly into our existing pipeline.
7. Source and Semantic Categories
For categorization, we also use additional features like the source of the document and other semantic category features like jobs, sales, etc. which are not useful for de-duplication. Just to give you some perspective, for one customer a total of 40,000 documents were sourced into the system in the past one week.
Approximately half of them were filtered as unimportant using preset rules and machine learning-based classification (to be discussed in detail in a later post). Out of the remaining, only ~15,000 documents were identified as unique. With just these two steps, we were able to reduce the number of documents for further processing by about 60%. Using de-duplication alone we have reduced the document space by about 25%.
A note on the Trade-off:
There is always this trade-off between using the best approach to solve the problems and the availability of computational resources. We had to let go of Latent Semantic Indexing, Inverse Document Frequency, K-means clustering, and higher n-grams for bringing in the same levels of computational resources.
But as we move higher and higher up the scale we will have to use the capabilities of distributed systems to de-duplicate millions of documents. The latest version of Apache Solr, which we already use as our market analysis search platform, comes with these capabilities.